
Today I am going to discuss a problem that should make you think of a wedding… It is the problem of assigning people to tables for a large banquet. Some people should be seated together (the bride and the groom for example), while other shouldn’t be at the same table (the groom’s uncle and his ex-wife for example)…
This problem has not come to my mind while planning my own wedding (we were only 27 people, so it wasn’t that difficult to assign people to seats… Moreover my wife did all the hard work, like to tell me to put a suit and to answer ‘yes’ to any questions…). However, when I was still a student I took part in the organization of a diner for 300 people. We had decided to give the opportunity to the guests to give a list a people they would like at their table, and other they couldn’t stand having at the same table. We were lucky enough that the guests were hypocritical enough not to name a single person they wouldn’t like to see at their table. But they were all happy to name a few people they would like to see at their table. It was a nightmare, it took us three nights to finally come up with a decent seating plan. The whole time I was complaining and saying that a day I would take some time to write a piece of software to automate the process.
This subject is going to be divided in two posts. In this first post, I am going to discuss two mathematical formulation for the problem of assigning guests to their tables. In a second post, I will discuss a heuristic method for a slightly more complicated version of the problem where we also want to assign the seats.
So, let’s try to define the problem a little bit more formally. We have a set of guests 




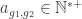



For simplicity reason we are going to assume that there are exactly as many seats as there are guests. I am first going to propose a very straightforward model for this problem, let’s first introduce some notations :

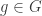

The model is the following :

s.t.


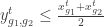
The constraints (1) ensure that each guest is assigned to exactly one table. Constraints (2) guarantee that the capacity of the tables are respected. Finally constraints (3) ensure that 
UPDATE :
As pointed out by @JFPuget, constraints (3) can be replaced by :
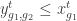

which gives a tighter relaxation. The experiments now reports the results with this improved model.
When we consider a problem with homogeneous tables (tables all having the same number of seats), this model offers a lot of symmetries as any table can be substituted by any other. For this reason let’s consider an alternative model, for the case where all the tables have the same number of seats. Let us introduce the following notation :




The model is the following:

s.t.

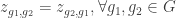

The constraints (4) ensure that each guest is seated with 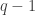

So how does those two models behave ?
I have generated some random models with number of guests ranging from 8 to 40 and table size from 4 to 10. I have also generated an instance where I have manually generated the affinity matrix of the people present at my own wedding (this instance correspond to the bold line in the result table). I have set a time limit of 900 seconds and report t.o. when the time limit is exceeded, otherwise run time are reported in seconds. The models are solved using GLPK.
UPDATE : out of curiosity I have added the results using CPLEX 12.4.0.0 as a MIP solver.
| GLPK | CPLEX | ||||
| Guests | Table Size | Model 1 | Model 2 | Model 1 | Model 2 |
| 8 | 4 | 1.2 | < 0.1 | 0.14 | < 0,1 |
| 15 | 5 | t.o. | 0.4 | 39.44 | < 0.1 |
| 20 | 5 | t.o. | 3.8 | t.o. | 0.6 |
| 20 | 10 | t.o. | 5.7 | t.o. | 1.03 |
| 27 | 9 | t.o. | 343.5 | t.o. | 50.2 |
| 27 | 9 | t.o. | 14.5 | t.o. | 0.7 |
| 32 | 8 | t.o. | 251.0 | t.o. | 74.9 |
| 40 | 8 | t.o. | t.o. | t.o. | t.o. |
As a conclusion of the first part of this post, what can we say ?
1/ Instance based on real-life data seems to be easier to solve, as the affinity matrix is somehow more structured, which apparently makes it easier to build consistent tables.
2/ Getting ride of symmetries helps (A LOT!!! The speed up is greater than 1800x on the second instance).
3/ If you plan on using one of these models for your wedding, I hope that you are not planning to have too many guests 😉
If you are interested, the two models (coded in python using pulp) as well as the instance generator, the instances used in this post, and the real-life instances of my wedding (one with the real heterogeneous tables, and one with “fake” homogeneous tables) are available on bitbucket: https://bitbucket.org/renaud_masson/seat-planner
If you have any model enhancement ideas, suggestions or remarks, feel free to post in the comments section. Stay tuned for the second part of this post…

Nice post. Your constraint (3) could be made tighter with:
y_{g_1,g_2}^{t} \leq x^{t}_{g_1}
y_{g_1,g_2}^{t} \leq x^{t}_{g_2}
That’s right 🙂
I’ll try to add it to see how much it improves the results of the first model
Pingback: Planning your wedding is not easy… (Second part) | OR & Tricks